
Route hard or don’t route at all.
It’s only a day since Fable 5 has been suspended but damn don’t I miss it already. Other than OpenAI’s o3 and Anthropic’s Opus 4.5, few models have felt as big of a step change as Fable has. That said, it was token-hungry and pretty expensive. Reasonably, everyone’s only got one thing in their minds. What if we plan with a smart expensive model, implement with a cheap one, then review with the smart one. It’s something I spend alot of my braincells on while working with agents.1
There are variations of solutions to this. More on this below. I think if you are somewhat price-conscious, you probably do something similar. I figured I’d do some napkin math to get a sense of how the tradeoffs compare. The most significant consideration, other than output quality, is the cost of caching, especially with open-source models such as the DeepSeek V4 and MiMo v2.5 series.
The setup and some assumptions
A lot of variables are at play here so I’m assuming a few things to simplify the math. It’s napkin math, after all.
- A pretty big assumption is that you get roughly the same output quality from an assortment of open-source and frontier models vs frontier-only ones. This generally depends on the task, but my personal experience and belief is that it’s probably closer to valid than invalid for 75% of the tasks especially with a good harness. If not, it will be true pretty soon.
- That you’re using a multi-model harness like OpenCode, Pi, Codex, or custom, where you can point different phases at different providers and the harness handles tool format translation and any other disparities.
- This is primarily an interactive agent session, not super long-horizon tasks like goal, autoresearch, background agents etc, which probably look different.
- For a typical coding session, you’ve got three phases. Let’s say about 2 turns for the “plan” phase, about 2 for the “review” and the remainder for the long read-edit-run implementation loop (call it 15 turns). You certainly could have a more granular distinction within the implementation loop itself but I’m ignoring that for now.
- You spend on average about 2k output tokens. If your real average is 5K, every break-even shrinks and routing pays faster.
- Fresh input per turn is about 1k tokens.
- Context grows linearly at about 4k per turn. Previous response (~2K) + new message (~1K) + tool results (~1K) get appended to the prefix each turn. Real growth is bursty though.
- A 200K context window, which in my experience is around what works well before the agent starts getting dumber. Context starts at ~30K (system prompt, files, tools - this depends on your agent), grows roughly 4K per turn, and lands at ~98K by the end of implement. That’s well under the ~160K compaction threshold, so no compaction fires in this session.
- I assume a cache TTL of 5 minutes, which is Anthropic’s default. Their 1-hour TTL (which is 2x the write cost) would keep your review model’s cache alive through implement and change the return-trip math, but that’s probably less suited for most interactive agent sessions.2
- I assume each turn completes in under 5 minutes — meaning the tool execution between two consecutive API requests stays inside the TTL window. The cache TTL resets on reads, not just writes, so the clock that matters is time between API calls, not total session time. If a tool (test suite, build, deploy) takes longer than 5 minutes, the cache expires before the tool result is sent back, and that turn pays cold prices. “Stay warm” is a lower bound: real implement costs land somewhere between the warm and cold numbers depending on how fast your tooling runs. If your tools regularly blow past 5 minutes, the 1-hour TTL is worth it — you pay 2× the base input price to write (vs 1.25× for the 5-min default), but avoid repeated cold reads on every slow turn.
- I also assume you know when plan ends and implement starts. In practice, they can and often do blur. You can also do all sorts of things like small classifiers/RL etc.
- I also assume 100% cache hit if warm, 0% if cold. Partial hits happen when the prefix mostly matches but something changed (a tool result, a re-read file). Real cost sits between the cold and warm numbers.
Some things I don’t factor in are:
- Reasoning/thinking tokens. Extended thinking bills thinking tokens as output ($25/MTok on Opus, varying on others). A model that thinks for 10K tokens before writing 2K of code is really generating 12K at output rates. If your models use extended thinking, the output term is larger than shown and break-evens shift accordingly.
- Cache write premium. Anthropic charges 1.25x base input to write the cache on first use. Makes every switch slightly worse than shown, which nudges same-family routing further into “not worth it.”2
With that out of the way, let’s get it. The one rule that matters: a model’s cache is its own. The first turn after you switch to a model, it has never seen your conversation, so it reads the whole prefix cold at full input price. Every turn after, that prefix is cached at about a tenth of the price.
Prices (per million tokens as of today)34567.
| Model | Input | Cached | Output |
|---|---|---|---|
| Claude Fable 5 | $10 | $1 | $50 |
| Claude Opus 4.8 (and 4.6) | $5 | $0.50 | $25 |
| Claude Sonnet 4.6 | $3 | $0.30 | $15 |
| GPT-5.5 | $5 | $0.50 | $30 |
| GPT-5.4 | $2.50 | $0.25 | $15 |
| MiMo v2.5 Pro | $0.435 | $0.0036 | $0.87 |
| DeepSeek V4 Pro | $0.435 | $0.0036 | $0.87 |
| Kimi K2.6 | $0.95 | $0.16 | $4 |
A turn has two prices.
Cold turn = (prefix + new) × input + output × output-price. Warm turn swaps the prefix to the cached rate. We’ll start at the first implementation turn, after two “plan” turns. So we are at about 38K prefix (30K start + 2 turns × 4K).
For Fable 5 at this turn plus 1K new, 2K output:
cold: (0.038 + 0.001)×$10 + 0.002×$50 = $0.390 + $0.100 = $0.490
warm: 0.038×$1 + 0.001×$10 + 0.002×$50 = $0.038 + $0.010 + $0.100 = $0.148
The cold turn is over 3x the warm one. And for Opus 4.8:
cold: (0.038 + 0.001)×$5 + 0.002×$25 = $0.195 + $0.050 = $0.245
warm: 0.038×$0.50 + 0.001×$5 + 0.002×$25 = $0.019 + $0.005 + $0.050 = $0.074
That gap is the entire cost of switching, and it scales with how expensive the model’s input is. These are at the 38K starting prefix; by turn 15 the prefix reaches ~98K, and each warm turn costs about 40% more than at the start.
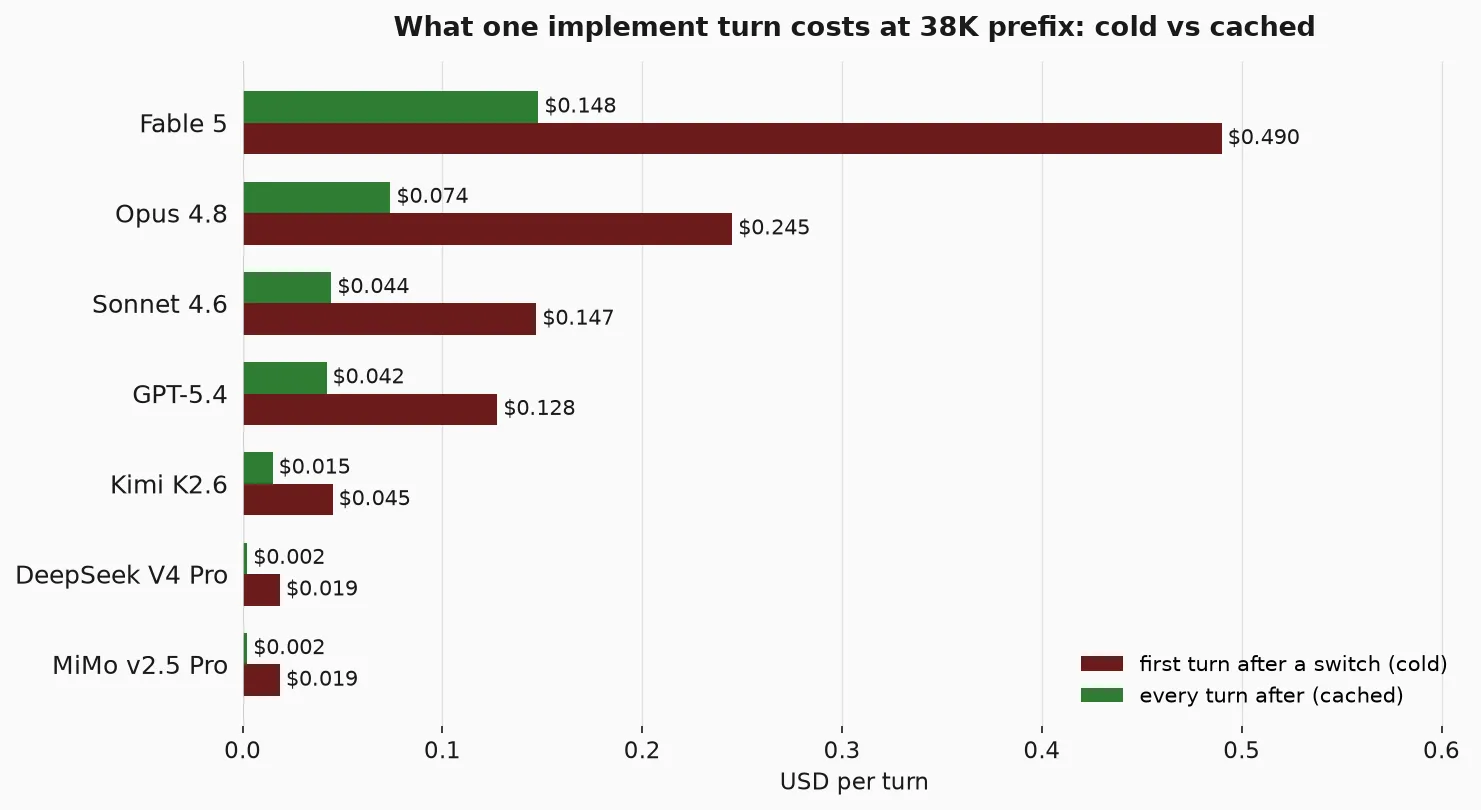
Nothing too surprising here. The premium model is never as expensive as the sticker price once caching kicks in.
All three phases, end to end
Every strategy starts cold on its plan model (nobody’s cache is warm at the start of a session), so plan always costs 1 cold turn + 1 warm turn. Context grows through the session: ~30K during plan, ~38K at the start of implement growing to ~98K by the end, and ~98K during review. All totals below account for this growth.
Plan phase (2 turns, starting at 30K prefix).
| Plan model | Turn 1 (cold, 30K) | Turn 2 (warm, 34K) | Plan total |
|---|---|---|---|
| Fable 5 | $0.410 | $0.144 | $0.55 |
| Opus 4.8 | $0.205 | $0.072 | $0.28 |
| GPT-5.5 | $0.215 | $0.082 | $0.30 |
Implement phase (15 turns, prefix growing 38K to 98K). If you stay on your plan model, its cache is still warm from planning, so all 15 turns pay the cached rate (growing each turn as context accumulates). If you switch in a new model, its first turn is a cold read at 38K and the remaining 14 are cached but growing.
| Implement model | Scenario | Impl total |
|---|---|---|
| Fable 5 | stay (all warm) | $2.64 |
| Opus 4.8/4.6 | stay (all warm) | $1.32 |
| Sonnet 4.6 | switch in (1 cold + 14 warm) | $0.89 |
| GPT-5.4 | switch in | $0.82 |
| Kimi K2.6 | switch in | $0.32 |
| MiMo v2.5 Pro | switch in | $0.05 |
| DeepSeek V4 Pro | switch in | $0.05 |
Sonnet saves about $0.43 over staying on Opus. Hold that number.
Review phase (2 turns, prefix now at ~98K). If you stayed on the same model through implement, its cache is still warm and review is cheap. If you routed away for implement, your review model’s cache expired during those 15 turns (caches invalidate after 5 minutes by default2), so review pays a cold read of the now-fat 98K context.
| Review model | Scenario | Turn 1 | Turn 2 (warm) | Review total |
|---|---|---|---|---|
| Fable 5 | stay (warm) | $0.208 | $0.212 | $0.42 |
| Fable 5 | switch back (cold) | $1.090 | $0.212 | $1.30 |
| Opus 4.8 | stay (warm) | $0.104 | $0.106 | $0.21 |
| Opus 4.8 | switch back (cold) | $0.545 | $0.106 | $0.65 |
| GPT-5.5 | switch back (cold) | $0.555 | $0.116 | $0.67 |
The review cold read on Opus at 98K costs an extra 0.44 over staying warm. That’s just barely more than the 0.43 you saved on implement. Now adding all three phases up:
Session totals (plan + implement + review):
| Strategy | Plan | Implement | Review | Total |
|---|---|---|---|---|
| All Fable 5 | $0.55 | $2.64 | $0.42 (warm) | $3.61 |
| Fable chimera (F/MiMo/F) | $0.55 | $0.05 | $1.30 (cold) | $1.90 |
| Claude routed (Op/Son/Op) | $0.28 | $0.89 | $0.65 (cold) | $1.82 |
| Codex routed (5.5/5.4/5.5) | $0.30 | $0.82 | $0.67 (cold) | $1.79 |
| All Opus 4.8 | $0.28 | $1.32 | $0.21 (warm) | $1.81 |
| Kimi routed (Op/Kimi/Op) | $0.28 | $0.32 | $0.65 (cold) | $1.25 |
| Cross-provider (Op/MiMo/5.5) | $0.28 | $0.05 | $0.67 (cold) | $1.00 |
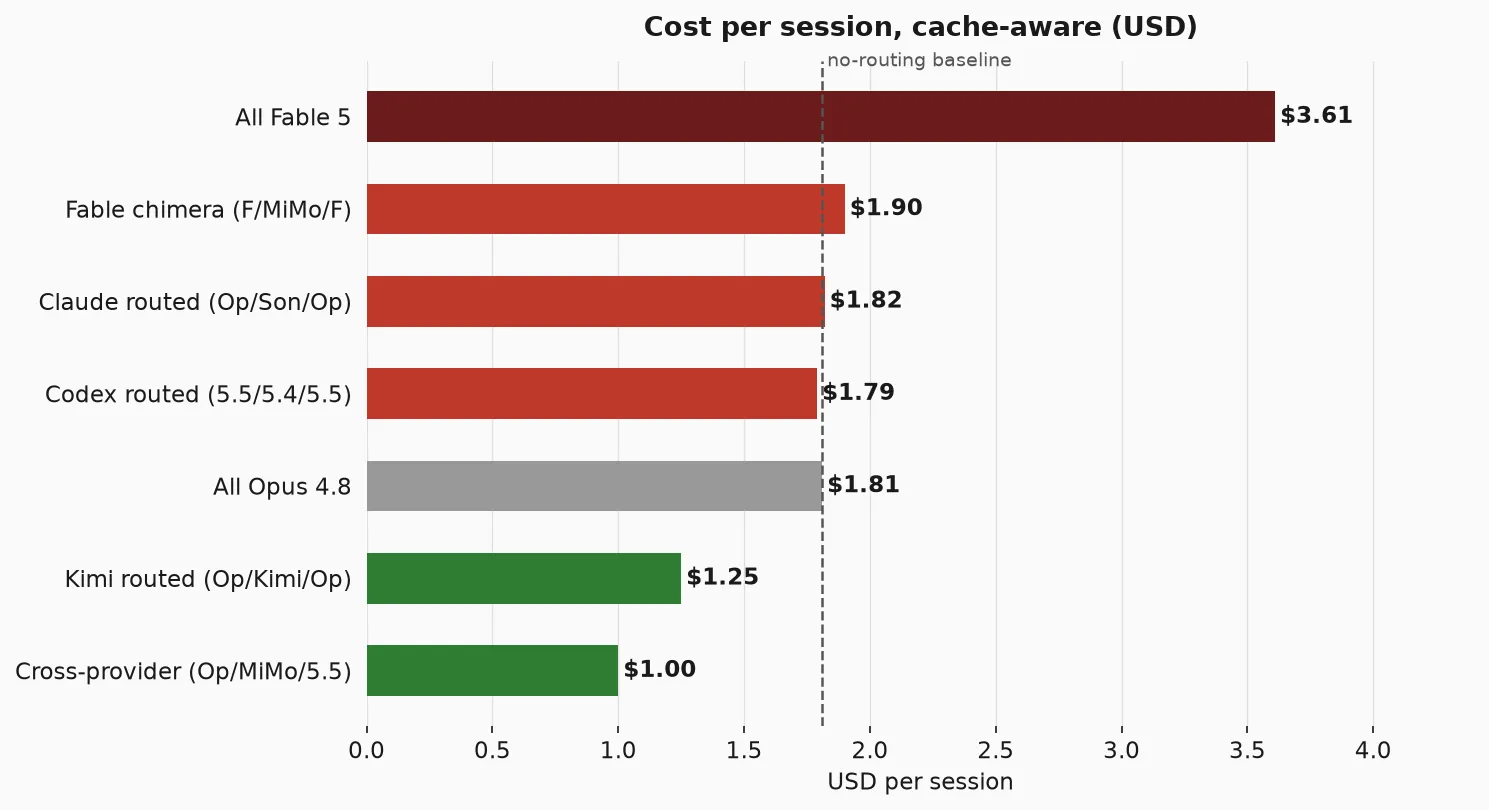
Routing Opus to Sonnet and back loses money. The two cold reads (out and back) eat the thin savings, and the return trip is worse than it looks because by review time the context has grown to 98K so the cold read is fat. The only same-family routing that clearly pays is from Fable, because Fable’s warm rate is 2x Opus’s, so the gap is wide enough to survive the return trip.
Hmm. So when does routing actually pay?
Same formula: the cold read is a one-time tax, you save a bit each turn, break even after enough turns.
prefix × (B_input − B_cached)
turns to break even = -------------------------------------------
prefix×(A_cached − B_cached)
+ output×(A_output − B_output)
+ new_input×(A_input − B_input)
At the starting 38K prefix with 2K output per turn:
| Swap | Cold tax | Saved/turn | Break-even |
|---|---|---|---|
| Opus 4.8 → Sonnet 4.6 | $0.10 | $0.030 | ~4 turns |
| GPT-5.5 → GPT-5.4 | $0.09 | $0.042 | ~2 turns |
| Fable 5 → Sonnet 4.6 | $0.10 | $0.104 | ~1 turn |
| Opus 4.8 → Kimi K2.6 | $0.030 | $0.059 | <1 turn |
| Opus 4.8 → DeepSeek V4 Pro | $0.016 | $0.072 | <1 turn |
| Opus 4.8 → MiMo v2.5 Pro | $0.016 | $0.072 | <1 turn |
| Fable 5 → MiMo v2.5 Pro | $0.016 | $0.146 | <1 turn |
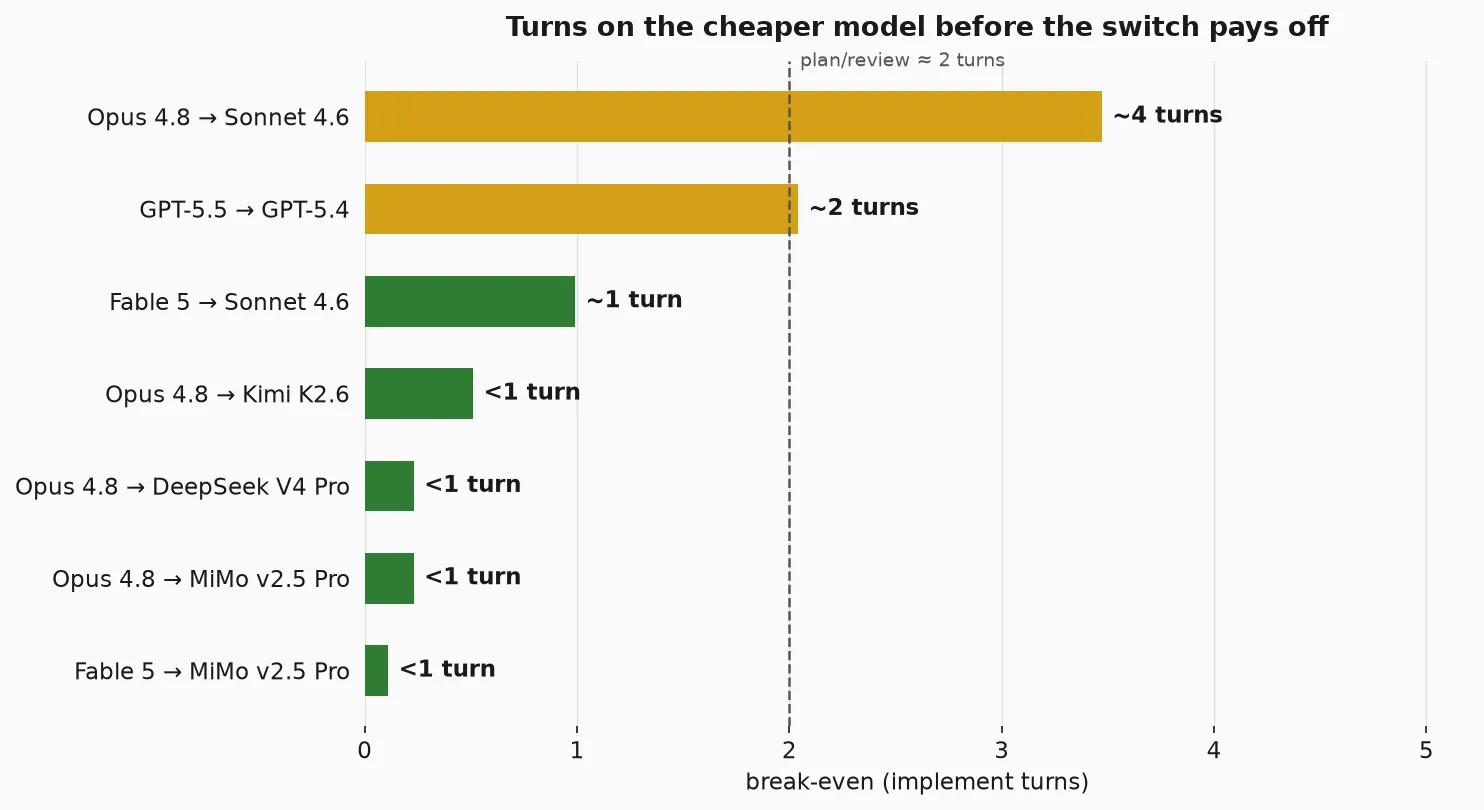
A one-notch downgrade (Opus to Sonnet) needs ~4 turns just to recoup one cold read, and you pay it twice if you bounce back. A cross-provider drop to MiMo, DeepSeek, or Kimi breaks even in under one turn — MiMo and DeepSeek output is now ~29x cheaper than Opus, so even a single turn of saved output more than covers the cold read.
And from Fable the gap is even bigger. Fable to Sonnet breaks even in ~1 turn instead of the ~4 it takes from Opus, because Fable’s cached rate is 0.50, so you save more per warm turn. Fable to MiMo pays for itself immediately.
As the prefix grows through the session these break-evens actually improve slightly, because the per-turn savings scale with prefix size while the cold tax was already paid. But there’s a more important variable: output per turn.
| Output/turn | Opus → Sonnet | Opus → Kimi | Opus → MiMo |
|---|---|---|---|
| 200 tokens (a rename) | ~9 turns | ~1 turn | ~1 turn |
| 500 tokens (add a flag) | ~7 turns | ~1 turn | ~1 turn |
| 2K tokens (new endpoint) | ~4 turns | <1 turn | <1 turn |
| 4K tokens (CRUD + tests) | ~2 turns | <1 turn | <1 turn |
| 8K tokens (scaffold a service) | ~1 turn | <1 turn | <1 turn |
Output size is the break-even. A session of small edits favors staying put. A session of writing big chunks of new code favors routing hard.
A note on compaction
With a 200K window our 19-turn session peaks at ~106K and never hits the ~160K compaction threshold. When compaction fires it rewrites the prompt, which invalidates the cache for every model, including the one you stayed on. Your “stay warm” model eats a cold read just like a model you switched into. This actually makes routing look better, because it erodes the stay-warm advantage. If your sessions regularly compact, the numbers above are conservative and routing pays more readily.
Tool support
Routing is supported by some tools. Cursor’s auto mode8, Martian9, subagents, Droid’s Router10, OpenRouter11 (which seems to have a few types). Some other approaches implement routing in the harness layer via a meta-harness. Though the motivation there seems to be less on cost and more on leveraging frontier labs RL-ifying their harnesses for their models. An alternative approach that I’ve grown to like is an advisor tool/agent that can be referenced by a weaker model for the tricky cases either mid-generation or after N turns. Oh my Pi exposes this as a watchdog background agent12 while Claude13 and OpenRouter14 expose them as tools that the executor can call. OMP’s advisor model has read-only workspace access, severity-based interruption, and lets you define project-specific review rules that only the advisor sees, not the primary agent. It’s been one of the best ways I’ve been able to be productive with the MiMo and DeepSeek models, especially for doing autoresearch experiments because the advisor can catch things the executor overlooked.
Conclusion
Like everything else, it depends on your use case. Certainly, as we’ve seen, the price gap between your anchor model and your implement model matters. Small gap (Opus to Sonnet) means thin per-turn savings that the cold reads eat. Big gap (anything to MiMo/DeepSeek/Kimi, or Fable to Sonnet) means the savings dwarf the switch cost.
The phase length also matters. Short phases (plan, review at ~2 turns) don’t clear the break-even for same-family swaps. The implement phase at 10 to 20 turns clears everything. That said, if MiMo v2.5 Pro flubs it and you spend three Opus turns cleaning up, then the savings evaporate. Today’s cheap coders (Kimi K2.6, DeepSeek V4 Pro, MiMo v2.5 Pro) are strong on SWE-style work, so it is plausible to make it work.
Is per-phase routing mostly a trap? Currently, I don’t think anyone’s really solved it yet. Even the providers above try to maintain session-stickiness, so they mostly just end up routing the initial prompt, which might not work too well for easy-looking tricky bugs or ambiguous prompts. They also often don’t allow you granular enough visibility into what’s routed when and why. The two cases that I think work great for scoped tasks are routing from Fable (hopefully back soon), where the gap is wide enough to survive a round trip, or going cross-provider to a genuinely cheap implement model and staying there for the whole grind using a generated plan artifact.
Footnotes
-
Original tweet / discussion — https://x.com/bnjorogedev/status/2050736215750496326?s=20 ↩
-
Anthropic prompt caching — TTL, write/read multipliers — https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching ↩ ↩2 ↩3
-
Claude model and caching pricing — https://platform.claude.com/docs/en/about-claude/pricing ↩
-
OpenAI GPT-5.5 and GPT-5.4 pricing — https://openai.com/api/docs/pricing ↩
-
DeepSeek V4 Pro pricing — https://api-docs.deepseek.com/quick_start/pricing ↩
-
Kimi K2.6 pricing (Moonshot official API) — https://platform.kimi.com/docs/pricing ↩
-
MiMo v2.5 Pro pricing (Xiaomi API, prices reduced May 2026) — https://openrouter.ai/xiaomi/mimo-v2.5-pro ↩
-
Cursor auto mode — https://cursor.com/docs/models-and-pricing ↩
-
Martian RouterBench — https://withmartian.com/post/introducing-routerbench#1-%C2%B7-introduction ↩
-
Droid’s Router — https://factory.ai/product/router ↩
-
OpenRouter auto-router — https://openrouter.ai/docs/guides/routing/routers/auto-router ↩
-
oh-my-pi advisor-watchdog — https://github.com/can1357/oh-my-pi/blob/main/docs/advisor-watchdog.md ↩
-
Claude advisor tool — https://platform.claude.com/docs/en/agents-and-tools/tool-use/advisor-tool ↩
-
OpenRouter advisor server tool — https://openrouter.ai/docs/guides/features/server-tools/advisor ↩